Hoofdstuk 11. Informatiemodellering
Bij het ontwerpen van een database komt heel wat kijken. |
| Artikelgroep | Artikelnaam | Verkoopprijs | Inkoopprijs Mergelland | Inkoopprijs Betuwe | Inkoopprijs Zeeland | Inkoopprijs Achterhoek |
| Appel | Jonagold | 8,50 | 4,75 | 5,50 | ||
| Appel | Elstar | 9,00 | 6,00 | 5,50 | ||
| Peer | Conference | 7,50 | 4,00 | 3,50 |
Deze tabel lijkt wel te voldoen, totdat er een nieuwe leverancier bijkomt.
Achteraf nog een kolom toevoegen is lastig.
En de groenteboer zou graag wat meer gegevens van de leveranciers in de database hebben, bijvoorbeeld de telefoonnummers. En dat is in dit ontwerp moeilijk te realiseren.
Ook overzichten per bedrijf zijn moeilijk te maken doordat verschillende leveranciers in verschillende kolommen staan.
Je zou voor elke leverancier een aparte query moeten maken, je kunt niet volstaan met één query die je voor alle leveranciers kunt gebruiken.
Je spreekt hier van een ontwerp met herhaalde kolommen, en dat moet je proberen te voorkomen.
Zijn tweede poging ziet er zo uit:
| Artikelgroep | Artikelnaam | Verkoopprijs | Leverancier | Telefoon | Inkoopprijs |
| Appel | Jonagold | 8,50 | Mergelland | 056-9876543 | 4,75 |
| Appel | Jonagold | 8,50 | Betuwe | 012-1234567 | 5,50 |
| Appel | Elstar | 9,00 | Mergelland | 056-9876543 | 6,00 |
| Appel | Elstar | 9,00 | Achterhoek | 051-5432198 | 5,50 |
| Peer | Conference | 7,50 | Zeeland | 06-54637842 | 3,50 |
| Peer | Conference | 7,50 | Mergelland | 056-9876543 | 4,00 |
Deze tabel lijkt wel te voldoen, totdat bijvoorbeeld één van de leveranciers een ander telefoonnummer krijgt.
Dan moet bij alle artikelen, die geleverd worden door die leverancier, het telefoonnummer worden veranderd.
Het kan dan heel gemakkelijk gebeuren dat bij een artikel van die leverancier vergeten wordt die wijziging aan te brengen.
En dan bevat de tabel dus een fout. Er staat dan tegenstrijdige informatie in de tabel: bij die leverancier staan twee verschillende telefoonnummers op twee verschillende plaatsen. Als er tegenstrijdige informatie in de database staat zeggen we wel dat de database inconsistent is.
En die fout ontstaat doordat hetzelfde telefoonnummer (en nog meer gegevens trouwens) meer dan één keer in de database staat, daardoor kun je allerlei problemen krijgen.
Dezelfde gegevens meer dan één keer in de database opnemen wordt redundantie genoemd, en dat moet je dus proberen te voorkomen.
 11.3 Feiten, objecten en labels
11.3 Feiten, objecten en labels
We gaan nu gebruik maken van FCO-IM, Fully Communication Oriented Information Modelling.Het analyseren met de methode FCO-IM begint met het formuleren van zinnen, waarin de gegevens waar het om draait in voorkomen.
Als voorbeeld nemen we een leerlingenadministratie van een school in Buitenpost.
Daar zijn o.a. de volgende gegevens van alle leerlingen vastgelegd:
- achternaam
- voornaam
- adres
- woonplaats
- geboortedatum
- klas
| leerlingnummer | Achternaam | Voornaam | Adres | Woonplaats | Geb_dat. | Klas |
| 10001 | Haarsma | Petra | Molenstraat 12 | Oostermeer | 15-8-1991 | V5C |
| 10002 | Jonker | Henk | Achtkant 23 | Buitenpost | 11-11-1991 | V5A |
| 10003 | Claus | Dominic | Langelaan 68 | Surhuisterveen | 1-6-1991 | V5C |
| 10004 | Nutma | Fokke | SimkeKloostermanlaan 14 | Kollum | 10-9-1990 | V5B |
| 10005 | Venema | Taeke | Hoofdstraat 122 | Harkema | 18-6-1990 | V5A |
Voorbeeldzinnen waarin deze gegevens zijn verwerkt:
Petra Haarsma woont op Molenstraat 12 in Oostermeer, ze is geboren op 15-8-1991, ze zit in klas V5C en ze heeft
leerlingnummer 10001
Henk Jonker woont op de Achtkant 23 in Buitenpost, hij is geboren op 11-11-1991, hij zit in klas V5A en hij heeft leerlingnummer 10002
Henk Jonker woont op de Achtkant 23 in Buitenpost, hij is geboren op 11-11-1991, hij zit in klas V5A en hij heeft leerlingnummer 10002
Deze lange zinnen kunnen we opsplitsen in kortere zinnetjes. En daar beginnen we altijd mee.
Bijvoorbeeld:
Petra Haarsma heeft leerlingnummer 10001
Dominic Claus heeft leerlingnummer 10003
Fokke Nutma is geboren op 10-9-1990
Taeke Venema is geboren op 18-6-1990
Henk Jonker is geboren op 11-11-1991
Petra Haarsma zit in klas V5C
Henk Jonker zit in klas V5A
Fokke Nutma zit in klas V5B
Petra Haarsma woont op het adres Molenstraat 12
Taeke Venema woont op het adres Hoofdstraat 122
Dominic Claus woont in Surhuisterveen
Taeke Venema woont in Harkema
Dominic Claus heeft leerlingnummer 10003
Fokke Nutma is geboren op 10-9-1990
Taeke Venema is geboren op 18-6-1990
Henk Jonker is geboren op 11-11-1991
Petra Haarsma zit in klas V5C
Henk Jonker zit in klas V5A
Fokke Nutma zit in klas V5B
Petra Haarsma woont op het adres Molenstraat 12
Taeke Venema woont op het adres Hoofdstraat 122
Dominic Claus woont in Surhuisterveen
Taeke Venema woont in Harkema
Feiten en feittypen
We kijken even speciaal naar de volgende drie feiten (i.p.v. zinnen wordt in FCO-IM de term feiten gebruikt):
Petra Haarsma zit in klas V5C
Henk Jonker zit in klas V5A
Fokke Nutma zit in klas V5B
Je ziet dat deze drie feiten allemaal van hetzelfde soort of type zijn, het gaat steeds over een leerling die in een
bepaalde klas zit.Henk Jonker zit in klas V5A
Fokke Nutma zit in klas V5B
Dat zie je ook aan de woorden in het midden van de zinnen, die zijn steeds "zit in klas".
Daarom geven we dit type zin aan met zit_in_klas .
Anders gezegd: dit feittype noemen we zit_in_klas .
Zo heb je hierboven nog meer feiten van hetzelfde type.
We hebben ook het feittype heeft_leerlingnummer, het feittype is_geboren_op, het feittype woont_op_het_adres en het feittype woont_in.
We geven het feittype dus steeds aan met de woorden in het midden van de zinnen, die steeds gelijk zijn. Dat is niet verplicht, maar het is wel handig.
Je zou het laatste feittype (woont_in) bijvoorbeeld ook wel woonplaats kunnen noemen, maar dat is niet handig omdat je waarschijnlijk het object aan het eind van de zin zo gaat noemen. Wat met een object bedoeld wordt lees je hieronder.
Objecten en objecttypen
De laatste drie feiten gingen allemaal over een leerling die in een bepaalde klas zit.Met de eerste woorden werd steeds een leerling aangeduid, en met het laatste woord een klas.
Die leerlingen en klassen noem je objecten.
Ook in de zinnen daarboven komen objecten voor, steeds zitten er in elk zinnetje twee objecten.
Dus de personen en zaken, die in de feiten voorkomen, noem je objecten.
Je zou bovenstaand feittype ook op de volgende manier kunnen weergeven, met zogenaamde invulblokken:

In de eerste rechthoek kan Petra Haarsma staan, maar ook Henk Jonker of Dominic Claus.
En in de tweede rechthoek kan V5C staan, maar ook V5B of V5A .
Objecten zijn dus dingen die in de invulblokken bij feittypen kunnen worden geplaatst.
De invulplaatsen noemen we ook wel rollen.
Bij andere modelleermethoden worden de objecten ook wel entiteiten genoemd.
De objecten Petra Haarsma en Henk Jonker en Dominic Claus zijn alledrie van dezelfde soort, het zijn alledrie personen. Dat wordt het objecttype genoemd; het objecttype in de eerste rechthoek is dus een persoon.
Ook de objecten V5C en V5B en V5A zijn van hetzelfde type: het objecttype klas.
Het objecttype in de tweede rechthoek is dus een klas.
Labels en labeltypen
De objecten worden op een bepaalde manier aangeduid.Petra Haarsma wordt met haar voor- en achternaam aangeduid. Ze had ook met haar leerlingnummer kunnen worden aangeduid, er had dus ook wel kunnen staan: Leerling 10001 zit in klas V5C
Of misschien kon er ook wel staan: De oudste dochter van J. Haarsma uit Oostermeer zit in klas V5C.
Maar dat is niet gebeurd, ze wordt met haar voor- en achternaam aangeduid, en dat wordt het label genoemd.
Je kunt het je voorstellen als een etiket, dat op het object wordt geplakt om aan te geven wat het is.
Ook het object, dat eventueel met leerling 10002 had kunnen worden aangeduid, is met het label voor- en achternaam aangeduid, namelijk met de naam Henk Jonker.
En ook bij de derde persoon is het label voor- en achternaam gebruikt.
Bij alle drie is hetzelfde labeltype gebruikt, namelijk voor- en achternaam.
We hadden eventueel ook het labeltype leerlingnummer kunnen gebruiken, maar dat is bij deze feiten niet gedaan.
Bij andere modelleermethoden worden de labels ook wel attributen genoemd.
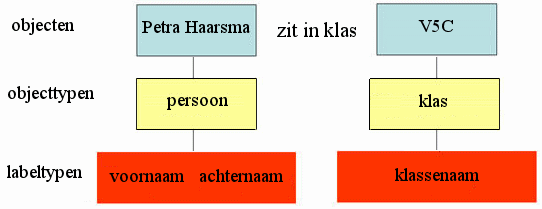
In bovenstaande figuur zie je het feittype zit_in_klas, met de bijbehorende invulvakken.
Op de bovenste regel zijn er objecten in de invulvakken geplaatst.
Daaronder (met gele achtergrond) zie je de objecttypen.
En daar weer onder (met rode achtergrond) de labeltypen.
We zouden het feittype nu ook op de volgende manier kunnen noteren:
<Persoon, aangeduid met zijn voornaam en achternaam> zit in klas <Klas, aangeduid met de klassenaam>
Het afleiden van een feittype met objecttypen en labeltypen uit een stel voorbeeldzinnen noemen we kwalificeren.
In het programma FCO-IM, dat we gaan gebruiken, worden de engelse termen qualify, facttype, objecttype en labeltype gebruikt.
11.4 Kwalificeren m.b.v. het programma FCOCASE
Het kwalificeren van zinnen doen we m.b.v. het programma FCOCASE.Er is ook een nieuwere versie van FCOCASE, die heet CaseTalk. Die kun je gratis downloaden van www.casetalk.com
De student-edition mag je, na registratie, 6 maanden gebruiken. Daarna kun je je eventueel weer voor 6 maanden registreren.
Maar de oude versie werkt ook prima, we leggen het uit aan de hand van die versie.
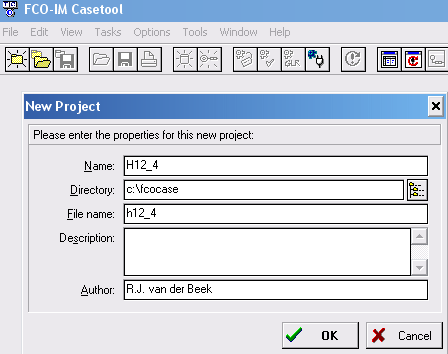
- Start het programma FCOCASE en kies voor een nieuw project.
- Dan krijg je onderstaand venster.
Geef het project, waarmee je wilt beginnen, een naam.
Die naam mag uit maximaal 8 tekens bestaan, en geen spaties bevatten! (dat komt doordat het een oude versie is)
Als je klikt op dan kun je de drive en de map aangeven, waarin het moet worden
opgeslagen.
dan kun je de drive en de map aangeven, waarin het moet worden
opgeslagen.
- Als je op OK klikt dan verschijnt er een venster waarbij in de titelbalk New IG staat.
IG is de afkorting van Informatie Grammatica, en dat betekent dat je nu zinnen kunt gaan "kwalificeren". Dus je kunt van zinnen aangeven wat het feittype is, en wat de objecttypen en labeltypen zijn.
- Klik op het icoontje voor New Expression
 , dan kun je een zin invoeren.
, dan kun je een zin invoeren.
Voer de volgende zin in: Petra Haarsma zit in klas V5C
Het eerste wat nu moet gebeuren, is een naam geven aan dit feittype.
Typ in het onderste venster, onder Object type / fact type: zit_in_klas
Gebruik geen spaties in de naam, en zorg er altijd voor dat er een werkwoord in voorkomt om verwarring met de objecten te voorkomen.
Klik op Qualify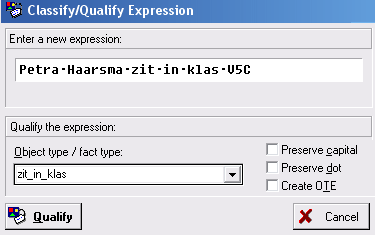
- Selecteer nu het zinsdeel Petra Haarsma en
geef aan wat het objecttype is: persoon.
Klik op Qualify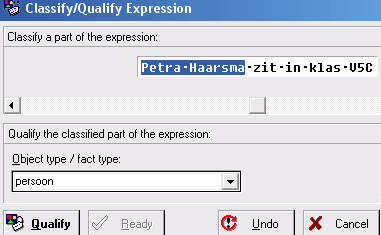
- Selecteer nu V5C en geef aan wat
het objecttype is: klas.
Klik op Qualify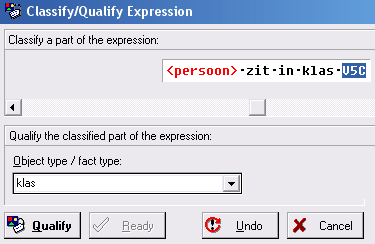
- Je ziet dat de oorspronkelijke zin is omgezet naar een zin met objectnamen.
De waarden van de objecten staan er onder.
Klik op Ready. - We gaan nu een niveau dieper werken, we gaan aangeven wat de labeltypen zijn.
Selecteer Petra en geef aan wat het labeltype is: voornaam
Klik op Qualify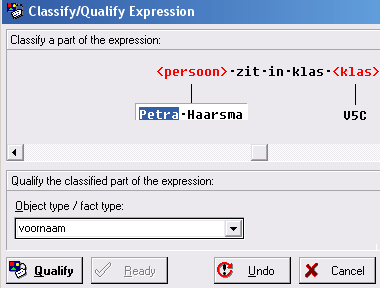
- Selecteer Haarsma en geef aan wat het labeltype is:
achternaam
Klik op Qualify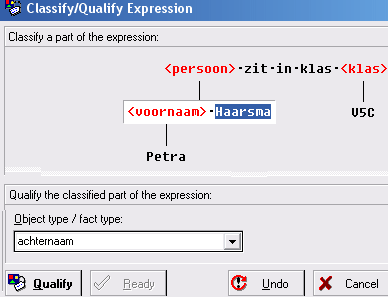
- Klik net zolang op Ready tot de cursor op V5C staat, selecteer V5C en
geef aan wat het labeltype is: klassenaam
Klik op Qualify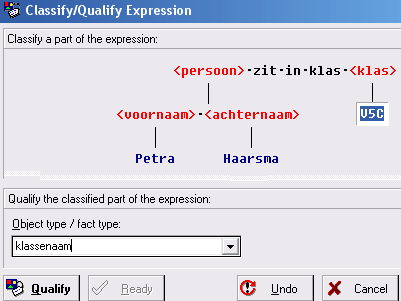
- Klik net zolang op Ready tot er OK verschijnt
De eerste zin is gekwalificeerd, het resultaat verschijnt nog even in beeld (zie hieronder), klik dan op OK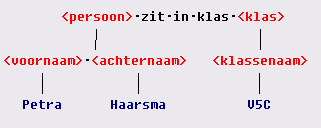
- Klik op het icoontje voor New Expression
- Het resultaat van het kwalificeren zie je in het IG-venster:
Er worden drie symbolen gebruikt:- objecttypen worden met een cirkel aangegeven: "persoon" en "klas"
- labeltypen worden met een gestippelde cirkel aangegeven: "voornaam" en "achternaam" en "klassenaam"
- feittypen worden met twee gekoppelde rechthoekjes aangegeven: "zit_in_klas"
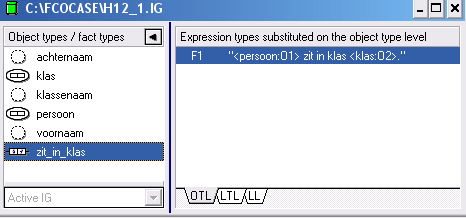
Als je op het feittype "zit_in_klas" klikt dan zie je in het rechter gedeelte van het venster de ingevoerde zin. - Als je klikt op het tabblad OTL (Object Type Level) dan zijn de objecten in de zin vervangen door de objecttypen, en die zijn genummerd.
- Als je klikt op het tabblad LTL (Label Type Level) dan zijn de objecten in de zin vervangen door de labeltypen.
- Als je klikt op het tabblad LL (Label Level) dan zie je de oorspronkelijke zin.
-
We gaan nog een zin invoeren.
- Klik weer op het icoontje voor New expression ,
dan kun je een nieuwe zin invoeren.
Voer de volgende zin in: Petra Haarsma woont in Oostermeer
Je moet als eerste weer een naam geven aan dit feittype, noem het: woont_in en klik dan op Qualify - Selecteer het zinsdeel "Petra Haarsma" en dan moet je aangeven wat het objecttype is.
Dat hoef je nu niet in te typen, want dat objecttype heb je al eerder gehad.
Klik op het pijltje in het venster voor het objecttype, dan verschijnen alle objecttypen, labeltypen en feittypen die we al gehad hebben. Klik op persoon, en dan op Qualify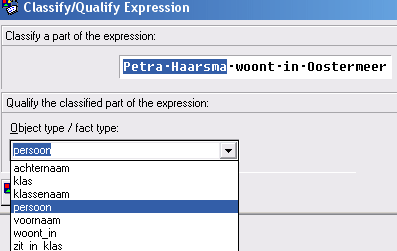
- Selecteer nu "Oostermeer" en geef aan wat het objecttype is: plaats, en klik op Qualify
- Dan zijn we klaar met het eerste niveau: de objecten hebben we gehad.
De zin wordt omgezet naar een zin met objectnamen, en de waarden van de objecten staan er onder.
- Zodra je op Ready klikt geeft het programma aan dat het de labeltypen bij het objecttype persoon al weet,
omdat die al eerder zijn ingevoerd.
Je hoeft alleen maar op Match te klikken om hiermee akkoord te gaan.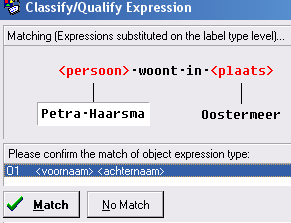
- Klik net zolang op Ready tot de cursor op Oostermeer staat,
selecteer Oostermeer en geef aan wat het labeltype
is: plaatsnaam
Klik op Qualify - Klik net zolang op Ready tot er OK verschijnt, dan ben je ook klaar met deze zin.
- Klik weer op het icoontje voor New expression
11.5 Het IGD m.b.v. het programma FCOCASE
Je kunt de structuur van zinnen goed aangeven m.b.v. een diagram (een tekening).Daarbij worden feittypen weergegeven door rechthoeken, objecttypen door cirkels en labeltypen door gestippelde cirkels.
Zo'n diagram of tekening wordt een IGD genoemd, dat is de afkorting van InformatieGrammaticaDiagram.
Je kunt dat heel eenvoudig maken m.b.v. het programma FCOCASE.
- Klik daarvoor op het icoontje voor New IGD

Er verschijnt een leeg venster, waar New IGD1 boven staat. - Je moet ook het IG-venster met alle feittypen, objecttypen en labeltypen in beeld hebben.
- Je kunt nu de feittypen, objecttypen en labeltypen uit het IG-venster naar het IGD-venster slepen.
Je kunt ze er één voor één naartoe slepen, maar je kunt ze er ook allemaal tegelijk naartoe slepen.
Wil je dat laatste, klik dan eerst op de bovenste in het IG-venster. Klik dan op de onderste, terwijl je de Shift-toets indrukt. Dan worden ze allemaal geselecteerd en dan kun je ze allemaal tegelijk verslepen.
De symbolen staan dan wel allemaal over elkaar heen, maar je kunt ze daarna nog verslepen.
- Je kunt het IGD mooier maken door de symbolen te verslepen. Maak er een overzichtelijk geheel van.
- Als je de feittypen, objecttypen en labeltypen van de eerste zin uit het IG-venster naar het IGD-venster hebt gesleept, dan
krijg je het volgende diagram:
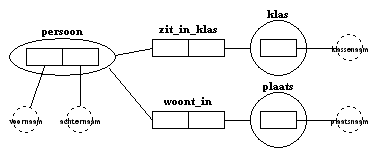
- Je ziet dat elk object (het symbool daarvoor is een cirkel) d.m.v. een lijntje
is verbonden
met een rechthoek van een feittype. Dat betekent
dat dat object kan worden ingevuld in die invulplaats, het kan een rol spelen bij dat feittype.
Verder is elk object, gesymboliseerd door een cirkel, d.m.v. een lijntje verbonden met een gestippelde cirkel, dat een label voorstelt.
Het is heel belangrijk dat je op de goede manier kwalificeert: steeds moet je eerst aangeven wat de naam van het feittype is, dan moet je de objecten benoemen, en daarna nog de labels.
Vergeet die laatste stap niet, want anders kan het programma de tabelstructuur niet ontdekken.
Het is dus heel belangrijk dat een gestippelde cirkel steeds verbonden is met een gesloten cirkel, bij elk object hoort immers een label.
- Misschien krijg jij een tekening met de ingevoerde zinnetjes onder de feittypen, en nummers in de vakjes.
Dat kun je eventueel uitzetten, daardoor wordt het misschien overzichtelijker.
Klik daarvoor in het menu op Options, en dan op Diagram Designer.
Door vinkjes te plaatsen of juist weg te halen kun je bepalen wat er bij de feittypen en objecttypen wordt gezet.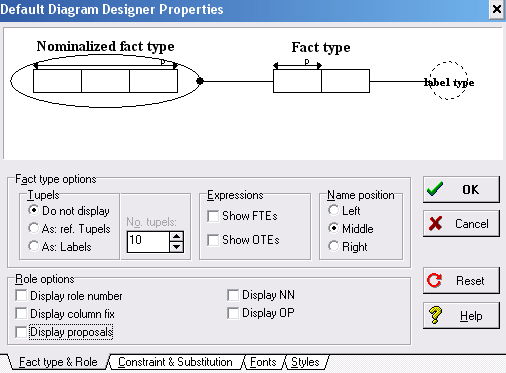
11.6 Elementaire feiten
Lange zinnen, zoals Petra Haarsma woont op Molenstraat 12 in Oostermeer, ze is geboren op 15-8-1991,
ze zit in klas V5C en ze doet aan tennis en hockey. Ze had voor Nederlands als rapportcijfer een 8, voor Engels een 7 en voor
Geschiedenis ook een 7 zijn niet geschikt om te analyseren en te kwalificeren.Je moet de informatie altijd eerst splitsen in zo kort mogelijke zinnen, en die korte zinnetjes worden elementaire feiten genoemd.
Je splitst bovenstaande zin in de volgende zinnetjes:
Petra Haarsma woont op Molenstraat 12
Petra Haarsma woont in Oostermeer
Petra Haarsma is geboren op 15-8-1991
Petra Haarsma zit in klas V5C
Petra Haarsma doet aan tennis
Petra Haarsma doet aan hockey
Petra Haarsma heeft voor Nederlands als rapportcijfer een 8
Petra Haarsma heeft voor Engels als rapportcijfer een 7
Petra Haarsma heeft voor Geschiedenis als rapportcijfer een 7
In de eerste zinnen komen steeds twee objecten voor.
In het bijbehorende feittype komen twee invulplaatsen, die ook wel rollen genoemd worden, voor. Een feittype met twee rollen noemen we een binair feittype.
In het IGD wordt een binair feittype getekend met twee rechthoeken, voor elke rol één.

De laatste zinnetjes bevatten drie objecten.
Als je de laatste zin Petra Haarsma heeft voor Geschiedenis als rapportcijfer een 7 opsplitst in twee zinnen:
Petra Haarsma heeft Geschiedenis
en Petra Haarsma heeft een 7
dan raak je informatie kwijt. Want als je alleen het laatste zinnetje leest, dan zie je wel dat Petra een 7 heeft, maar je weet niet voor welk vak het is.
De laatste zinnen kunnen dus niet gesplitst worden, het moeten feittypen met drie invulpaatsen blijven.
Een feittype met drie rollen wordt een ternair feittype genoemd, en in het IGD wordt een ternair feittype getekend met drie rechthoeken.

Je zou bijvoorbeeld als zinnetje ook nog kunnen toevoegen: er is een plaats Oostermeer
Dat zinnetje bevat maar één object, het bijbehorende feittype met één invulplaats wordt een unair feittype genoemd. Zo'n feit wordt ook wel een er-is-feit genoemd.
Het heeft weinig zin de unaire feittypen op te schrijven om de structuur van de database te ontdekken.
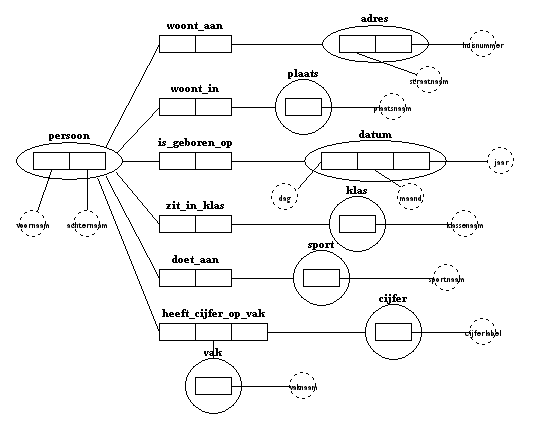
Je kunt beter binaire of ternaire feittypen bedenken, waarin het objecttype van het unaire feittype voorkomt. In het IGD wordt een objecttype daarom ook getekend als een cirkel, met daarin een rechthoek.
Die rechthoek stelt eigenlijk het unaire feittype voor dat betrekking heeft op dat objecttype.
Dat noemen we nominalisatie: een unair feittype wordt een objecttype.

Als je bovenstaande zinnen invoert, en daarna het IGD maakt, dan ontstaat het volgende diagram:
11.7 De uniciteits- en de totaliteitsbeperking
Voordat de structuur van de database aan de hand van het IGD bepaald kan worden moet er eerst nog iets
gebeuren.Uniciteitsbeperking
Bij elk feittype komen invulplaatsen voor. En nu is het belangrijk of er op zo'n invulplaats maar één ding ingevuld kan worden, of meer dan één.
Als het er maar één is dan wordt dat een uniciteitsbeperking genoemd.
Als voorbeeld nemen we het feittype zit_in_klas
Een paar voorbeeldzinnen maken duidelijk wat er met de uniciteitsbeperking bedoeld wordt:
Petra Haarsma zit in klas V5C
Dominic Claus zit in klas V5C
Petra Haarsma zit in klas V5A
Er zit een fout in bovenstaande zinnen, het is immers niet mogelijk dat Petra Haarsma in twee verschillende klassen zit.
De naam Petra Haarsma kan dus in de voorbeeldzinnen maar één keer voorkomen.
We noemen de invulplaats van het objecttype persoon daarom wel een unieke rol, het voldoet aan de unicitietsbeperking.
De rol van het objecttype klas is niet uniek, de klas V5C kan in meerdere zinnen voorkomen want een klas heeft meerdere leerlingen.
In het IGD is het mogelijk om de uniciteitsbeperkingen aan te geven. Je klikt in de werkbalk op Constraint Rollup

Dan verschijnt de volgende knoppenbalk:

Om aan te geven dat bij het feittype zit_in_klas de invulplaats van persoon voldoet aan de unicitietsbeperking selecteer je alleen het vakje van persoon (klik op het vakje terwijl je de Control-toets ingedrukt houdt) en klik je op:
Er verschijnt een pijl boven het vakje.
Bij het feittype woont_aan voldoet de invulplaats van persoon ook aan de unicitietsbeperking: een persoon kan maar op één adres wonen.
Je kunt dus ook een pijl zetten boven het linker hokje van het feittype woont_aan
(denk er om: er komt geen pijl boven de invulplaats van adres !)
Bij het feittype woont_in voldoet de invulplaats van persoon ook aan de unicitietsbeperking: een persoon kan maar in één plaats wonen.
Je kunt dus ook een pijl zetten boven het linker hokje van het feittype woont_in
Bij het feittype is_geboren_op voldoet de invulplaats van persoon ook aan de unicitietsbeperking: een persoon kan maar op één datum geboren zijn. Je kunt dus ook een pijl zetten boven het linker hokje van het feittype is_geboren_op
Bij het feittype doet_aan voldoet de invulplaats van persoon niet aan de unicitietsbeperking: een persoon kan op meer dan één sport zitten. Je kunt dus geen pijl zetten boven het linker hokje van het feittype doet_aan
Maar in een IGD moeten alle feittypen een uniciteitsbeperking krijgen, dus een pijl op het linker hokje of een pijl op het rechter hokje, of als dat niet klopt een pijl over het geheel.
Er kan ook geen pijl op het rechter hokje, want dat zou betekenen dat op elke sport maar één persoon zit.
Dan moet je een lange pijl zetten boven beide hokjes, want de combinatie van de persoon en de sport is wel uniek (het is onzin om de zin Petra Haarsma doet aan tennis twee keer op te schrijven, zo'n zin is dus uniek).
Dat doe je door op het feittype te klikken (dan worden beide hokjes geselecteerd) en dan te klikken op:
Bij het feittype heeft_cijfer_op_vak voldoet de invulplaats van persoon niet aan de unicitietsbeperking: een persoon kan in meer dan één zinnetje van dat soort voorkomen, hij of zij kan op verschillende vakken een cijfer hebben.
Je kunt dus geen pijl zetten boven het linker hokje van het feittype heeft_cijfer_op_vak
De invulplaats van vak voldoet ook niet aan de unicitietsbeperking: een vak kan in meer dan één zinnetje van dat soort voorkomen, anders zou er maar één persoon zijn die een cijfer op dat vak heeft.
Je kunt dus ook geen pijl zetten boven het middelste hokje van het feittype heeft_cijfer_op_vak
De invulplaats van cijfer voldoet ook niet aan de unicitietsbeperking, je kunt dus ook geen pijl zetten boven het rechter hokje van het feittype heeft_cijfer_op_vak
Maar de combinatie van de persoon en het vak is wel uniek.
Als Petra Haarsma voor Nederlands een 8 heeft kan ze niet tegelijk ook een 7 voor Nederlands hebben als rapportcijfer.
Er moet dus een lange pijl boven de twee linker hokjes.
Dat doe je door de twee linker vakjes te selecteren (klik op de vakjes terwijl je de Control-toets ingedrukt houdt) en dan te klikken op:
Er verschijnt een pijl boven de twee vakjes.
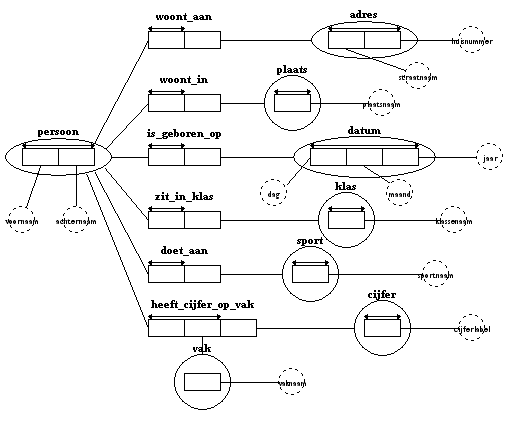
Ook de feittypen die in de cirkels zitten (dat zijn unaire feiten, die tot objecttype zijn gepromoveerd) moeten van een pijl worden voorzien.
Vaak zijn dat feittypen met maar een enkele rol, het is logisch dat die voldoen aan de unicitietsbeperking: je zult bijvoorbeeld geen twee klassen met dezelfde naam hebben, iedere klas komt dus maar één keer voor.
De objecten worden soms met een combinatie van twee of meer labels aangeduid: een adres wordt bijvoorbeeld aangeduid met de straatnaam en het huisnummer. De combinatie van straatnaam en huisnummer is natuurlijk uniek, en dus kan er een lange pijl boven die twee hokjes.
Als je alle uniciteitsbeperkingen aanbrengt dan ziet het IGD er als volgt uit:
Totaliteitsbeperking
Bij elk feittype komen invulplaatsen voor. We zagen hierboven dat het belangrijk is of er op zo'n invulplaats maar één ding ingevuld kan worden, of meer dan één.
Als het er maar één is dan wordt dat een uniciteitsbeperking genoemd.
Het is ook belangrijk om te weten of er bij elk object iets ingevuld moet worden. Als dat zo is dan wordt dat een totaliteitsbeperking genoemd.
De uniciteitsbeperking kun je omschrijven als: niet meer dan één keer.
De totaliteitsbeperking kun je omschrijven als: iedereen heeft er minstens één.
Als voorbeeld nemen we het feittype woont_aan
Heeft iedereen een adres? Er zijn misschien wel daklozen, die geen adres hebben, maar als het gaat om een database voor een school zal iedereen een adres hebben. Bij het beantwoorden van die vraag is de universe dus belangrijk: over welke gegevens gaat het?
Bij het feittype woont_aan voldoet de invulplaats van het objecttype persoon dus aan de totaliteitsbeperking.
In het IGD is het mogelijk om de totaliteitsbeperkingen aan te geven. Je klikt in de werkbalk op Constraint Rollup
Dan verschijnt de volgende knoppenbalk:
Om aan te geven dat bij het feittype woont_aan de invulplaats van persoon voldoet aan de totaliteitsbeperking selecteer je alleen het vakje van persoon (klik op het vakje terwijl je de Control-toets ingedrukt houdt) en klik je op:

Er verschijnt een dikke stip op de cirkel van het object persoon, op de plaats waar de verbindingslijn naar de rechthoek van het feittype woont_aan.
Bij het feittype woont_in voldoet de invulplaats van persoon ook aan de totaliteitsbeperking: elke persoon, die in de database van een school voorkomt, heeft een adres.
Je kunt dus ook een dikke stip zetten bij de verbindingslijn van persoon naar het feittype woont_aan
Bij het feittype is_geboren_op voldoet de invulplaats van persoon ook aan de totaliteitsbeperking: elke persoon heeft een geboortedatum.
Bij het feittype zit_in_klas voldoet de invulplaats van persoon ook aan de totaliteitsbeperking, tenminste als het een database betreft van leerlingen van een school: elke leerling, die in de database van een school voorkomt, zit in een klas.
Bij het feittype doet_aan voldoet de invulplaats van persoon niet aan de totaliteitsbeperking: niet elke persoon hoeft aan een sport te doen.
Bij het feittype heeft_cijfer_op_vak voldoet de invulplaats van persoon niet aan de totaliteitsbeperking: niet elke persoon hoeft een cijfer voor een bepaald vak te hebben.
De invulplaats van vak voldoet ook niet aan de totaliteitsbeperking: voor niet elk vak hoeven er cijfers te zijn. Misschien is een docent ziek geweest, zodat er geen cijfers zijn gegeven. Of misschien zit je in het begin van het jaar en zijn er helemaal nog geen cijfers gegeven.
De invulplaats van cijfer voldoet ook niet aan de totaliteitsbeperking, niet elk cijfer hoeft voor te komen op een rapport.
Als je alle totaliteitsbeperkingen aanbrengt dan ziet het IGD er als volgt uit:
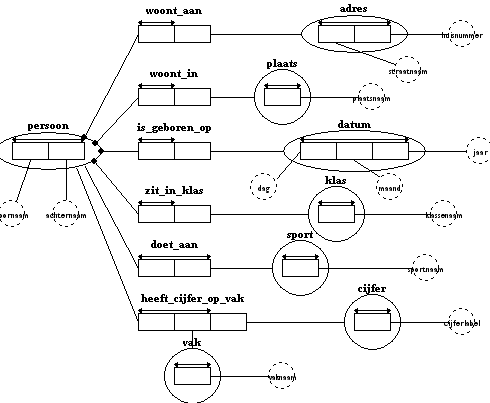
Bij het bepalen van totaliteitsbeperkingen moet je er om denken dat het tot gevolg heeft dat iets beslist moet worden ingevuld in de database, een kolom mag dan niet leeg blijven.
11.8 Groeperen: het ontwerp van de database
Als de beperkingsregels in het IGD zijn aangebracht is het model van de informatie klaar.Dan kan bepaald worden welke tabellen er voor de database nodig zijn, en welke kolommen er in de tabellen voorkomen.
Met de methode FCO-IM kan de database ontworpen worden.
Je kunt dat zelf doen, maar je kunt het FCOCASE ook laten doen.
Als je klikt op het GLR-icoontje (GLR=grouping, lexicalizing, reducing)
 dan gaat het programma
controleren of aan alle voorwaarden voldaan is. En als dat het geval is dan worden de tabellen gevormd.
dan gaat het programma
controleren of aan alle voorwaarden voldaan is. En als dat het geval is dan worden de tabellen gevormd.Je krijgt dan eerst het volgende venster:
Als je dan op Run klikt gaat het programma bezig.
Als je niet op alle feittypen en objecttypen een pijl hebt geplaatst krijg je een foutmelding en dan moet je dat eerst veranderen.
Soms krijg je ook nog waarschuwingen, maar daar hoef je je niets van aan te trekken.
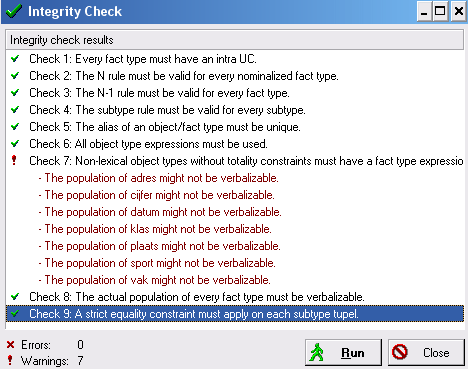
De controle bestaat uit negen onderdelen (checks), waarbij de checks 1 tot en met 3 van groot belang zijn.
Check 7 geeft vaak een groot aantal waarschuwingen waar we ons niets van aan hoeven te trekken.
We bespreken daarom alleen 1, 2, 3 en 7.
- Check 1
Every fact type must have an intra UC.
Dat betekent dat elk feittype een uniciteitsbeperking moet hebben.
Als er dus geen uniciteitsbeperking gevonden kan worden die één of enkele rollen bedekt, moet er een uniciteitsbeperking over alle rollen liggen. - Check 2
The N-rule must be valid for every nominalized fact type.
Dat betekent dat elk feittype, waar een bol omheen staat, een uniciteitsbeperking moet hebben die alle rollen bedekt. Dit heet de N-regel. - Check 3
The N-1-rule must be valid for every fact type.
Dat betekent dat elk feittype (waar geen bol omheen staat) hooguit één mag rol hebben waar geen uniciteitsbeperking overheen ligt. Dat heet de N-1-regel.
Reden: als er twee rollen buiten de uniciteitsbeperking vallen kun je het feittype splitsen. - Check 7
Non-lexical object types without totality constraints must have a fact type expression.
Een voorbeeld: Als je een model hebt waarin plaatsen voorkomen, omdat je van personen de woonplaats wilt vastleggen, dan hoort er bij de rol van (woon)plaats eigenlijk een totaliteitsstip te staan. Je neemt immers een plaats alleen op als het een woonplaats is. Die stip wordt vaak vergeten en het programma geeft daarvoor een waarschuwing. Als je je er niets van aantrekt heeft het verder geen gevolgen.
Als je de uniciteitsbeperkingen hebt aangebracht zoals in de figuur vlak boven 11.8 dan krijg je het volgende uitvoerrapport. Je ziet dat er wel enkele waarschuwingen zijn, maar dat er 0 Errors zijn.
Klik dan op Run en als alles goed gaat dan krijg je een nieuw IGD dat er als volgt uitziet:
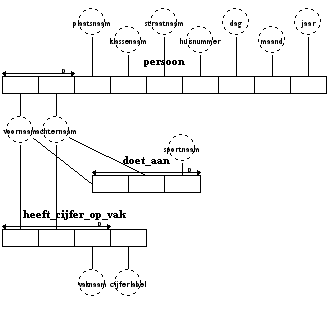
Je ziet dat er drie tabellen zijn, en je ziet ook uit welke kolommen die tabellen bestaan.
En je ziet ook wat de bijbehorende sleutelvelden zijn, dat zie je aan de pijlen die er boven staan.
Je kunt de volgorde van de vakjes eventueel nog veranderen.
Het is het meest logisch om in alle tabellen de voornaam en de achternaam vooraan te plaatsen.
Als dat niet zo is, en je wilt het vakje van de voornaam verschuiven, dan selecteer je het vakje van voornaam (klik op het vakje terwijl je de Alt-toets ingedrukt houdt) en je versleept het naar voren.
Hoe bepaal je welke tabellen er zijn, en wat er in die tabellen zit?
Je kunt volgen hoe het programma FCOCASE het doet, maar je moet het ook zelf kunnen!
Om het GLR-proces te starten kun je in onderstaand venster het vinkje voor Step-by-Step aanklikken.
Als je dan op Run klikt gaat het programma bezig, en dan kun je precies volgen wat er gebeurt.
Eerst verschijnt het volgende venster:
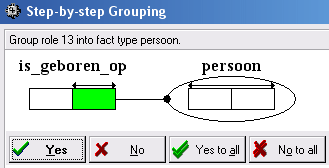
Het programma ziet dat een persoon maar één geboortedatum heeft (aan de pijl van de uniciteitsbeperking), en stelt voor om de geboortedatum in de tabel van de persoon (voornaam+achternaam) op te nemen. Het feittype is_geboren_op en het objecttype datum hebben dan hun dienst gedaan, en kunnen dan wel gemist worden.
Als je op Yes hebt geklikt verschijnt het volgende venster:
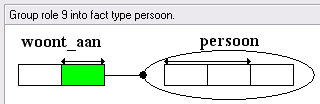
Het programma ziet dat een persoon maar één adres heeft (aan de pijl van de uniciteitsbeperking), en stelt voor om het adres in de tabel met voornaam+achternaam+geboortedatum op te nemen. Het feittype woont_op en het objecttype adres hebben dan hun dienst gedaan, en kunnen dan wel gemist worden.
Als je op Yes hebt geklikt verschijnt het volgende venster:
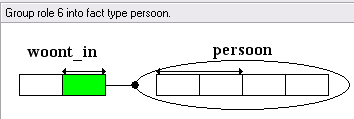
Het programma ziet dat een persoon maar één woonplaats heeft (aan de pijl van de uniciteitsbeperking), en stelt voor om de woonplaats in de tabel met voornaam+achternaam+geboortedatum+adres op te nemen. Het feittype woont_in en het objecttype plaats hebben dan hun dienst gedaan, en kunnen dan wel gemist worden.
Als je op Yes hebt geklikt verschijnt het volgende venster:
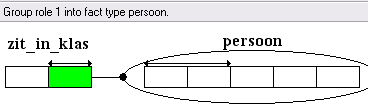
Het programma ziet dat een persoon maar in één klas kan zitten (aan de pijl van de uniciteitsbeperking), en stelt voor om de klas in de tabel met voornaam+achternaam+geboortedatum+adres+woonplaats op te nemen. Het feittype zit_in_klas en het objecttype klas hebben dan hun dienst gedaan, en kunnen dan wel gemist worden.
Dan zijn er nog twee feittypen over, die verbonden zijn met het objecttype persoon.
Er zit geen uniciteitsbepering op de rol persoon bij die feittypen, daarom worden daar aparte tabellen voor gegenereerd.
De ene tabel bevat dan de voornaam+achternaam van de persoon + sport.
De andere tabel bevat dan de voornaam+achternaam van de persoon + vak + cijfer.
11.9 De tabellen laten genereren in Access
Als het model in FCOCASE helemaal klaar is dan kun je er voor zorgen dat de tabellen, die volgens FCOCASE nodig zijn voor
de database, automatisch worden gegenereerd in Access.Daarvoor moet je in FCOCASE eerst nog het volgende doen:
Een visual basic programma laten genereren om de database te maken.
Als je klikt op Tasks (in de menubalk) en dan op Plug-in modules
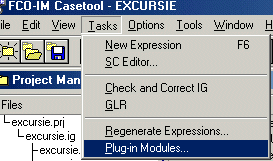
dan krijg je een venster waarin je uit verschillende programma's kunt kiezen.
Kies voor MS-Access 7.0 en klik dan op Invoke.
Bedenk een naam voor het programma dat gemaakt wordt, bijvoorbeeld h11.bas, en kies de map uit waarin het opgeslagen
moet worden.
Dan ben je klaar met FCOCASE, dat programma kun je afsluiten.
De database laten genereren in Access
Start nu Access op en kies in Access 2003 voor: Een nieuwe database maken en klik op het rondje voor Op basis van een lege database. Klik dan op OK
Bedenk een naam voor de database, en kies de map uit waarin de database moet worden opgeslagen.
Klik dan op Invoegen (in de menubalk) en dan op Module.
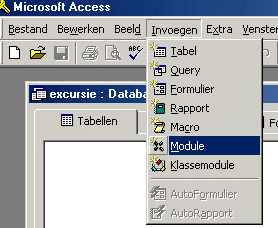
Klik weer op Invoegen, en dan op Bestand.
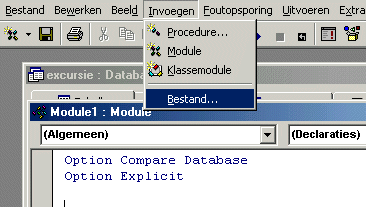
Dan verschijnt er een venster waarin je een bestand uit kunt kiezen.
Kies bij bestandstypen voor Basic-bestanden, en zorg er dan voor dat het basic-bestand, dat m.b.v. FCOCASE gemaakt is, wordt ingelezen.
In Access 2007 klik je op: Lege database, bedenk een naam voor de database, en kies de map uit waarin
de database moet worden opgeslagen. Klik dan op Maken
Klik dan in het lint op het tabblad Hulpmiddelen voor databases, en dan op Visual Basic
Klik dan in het lint op Invoegen en dan op Module.
Klik weer op Invoegen, en dan op Bestand.
Dan verschijnt er een venster waarin je een bestand uit kunt kiezen.
Kies bij bestandstypen voor Basic-bestanden, en zorg er dan voor dat het basic-bestand, dat m.b.v. FCOCASE gemaakt is, wordt ingelezen.
Klik dan in het lint op het tabblad Hulpmiddelen voor databases, en dan op Visual Basic
Klik dan in het lint op Invoegen en dan op Module.
Klik weer op Invoegen, en dan op Bestand.
Dan verschijnt er een venster waarin je een bestand uit kunt kiezen.
Kies bij bestandstypen voor Basic-bestanden, en zorg er dan voor dat het basic-bestand, dat m.b.v. FCOCASE gemaakt is, wordt ingelezen.
Dan verschijnt het visual-basic programma dat is aangemaakt met FCO.
Zet de cursor voor de regel: Public Sub FCO_CreateDatabase( )
en klik dan op Uitvoeren (op de menuregel) en dan op Ga naar/Doorgaan (in Access 2003) of op Sub/UserForm uitvoeren (in Access 2007).
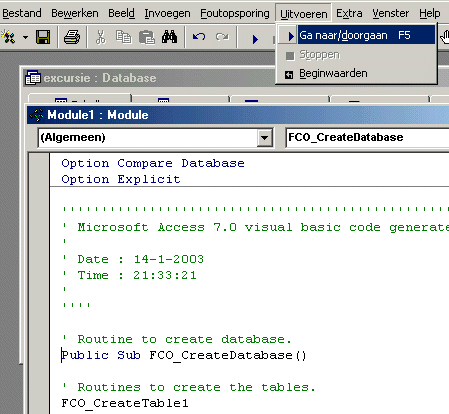
Als alles is goedgegaan dan zijn nu de tabellen aangemaakt.
Klik het visual Basic venster weg (ook de module, die hoeft niet bewaard te worden) en klik dan in Access 2003 eerst op Queries en dan op Tabellen, en dan staan de tabellen er.
In Access 2007 klik je op het pijltje achter Alle Tabellen, en dan op Gemaakt op, en dan staan de tabellen er.
Je moet nog wel even het aantal tekens dat je per veld mag gebruiken aanpassen, want het aantal dat automatisch is aangemaakt is waarschijnlijk te laag.
Verder zijn de namen van de kolommen waarschijnlijk niet naar wens, die krijgen automatisch de namen van de labeltypen die je hebt gebruikt in FCOCASE.
Maar die namen kun je in Access gemakkelijk veranderen.
Ook de namen van de tabellen kun je eventueel veranderen.
Als je op het tabblad tabellen klikt in Access dan krijg je de namen van de tabellen te zien, en die namen kun je daar dan eventueel veranderen (in Access 2003, in Access 2007 wil dat niet)
Als je de naam of het type van een kolom wilt veranderen dan moet je rechtsklikken op de naam van de bijbehorende tabel, en dan moet je (Access 2003) op Ontwerpen klikken, of (Access 2007) op Ontwerpweergave
En dan kun je daar in de linker kolom van het venster de namen van de velden eventueel veranderen.
In de rechter kolom van het venster staan de typen van de velden.
Als de database automatisch is aangemaakt dan is het type van alle velden tekst.
Als het inderdaad tekst is dan laat je dat gewoon staan, maar dan moet je in het venster er onder wel even de Veldlengte veranderen, die is meestal te klein.
Sommige velden wil je misschien van het type numeriek maken, en andere van het type datum, zodat er bij invoer gecontroleerd wordt of je een bestaande datum invoert.
Als je dat wilt veranderen dan klik je bij een datumveld in de type-kolom (waar Tekst staat), je klikt op het pijltje dat verschijnt en dan kies je datum/tijd uit.

